728x90
반응형
중복된 데이터를 삭제할때 pk가 있으면 pk를 쓰면 되지만
pk가 없는 경우에는 ROWID를 사용해서 중복데이터를 삭제할 수 있다
ROWID
ROWID는 ORACLE 에서 INDEX를 생성하기 위해 내부적으로 사용하는 PSEUDOCOLUMN으로 사용자가 임의로 변경하거나 삭제할 수 없다.
ROWID는 테이블에 데이터를 입력하면 자동으로 생성되고 각각 고유의 값을 갖게 된다.
| 000000 | 000 | 000000 | 000 |
| 오브젝트 번호 | 상대 파일 번호 | 블록 번호 | 블록 내 행번호 |
ex) AAAdtzAAaAAEe0bAAA
1. 오브젝트 번호 : 오브젝트의 고유 번호
2. 상태 파일 번호 : 테이블스페이스에 속해있는 데이터 파일에 대한 상대 파일번호
3. 블록 번호 : 데이터 블록의 위치를 알려주는 번호
4. 블록 내 행번호 : 오라클 블록의 헤더에 저장된 row directory slot의 위치를 알려주는 고유 번호
중복데이터 조회
select p.*
from (select SIDO,
SIGUNGU,
UPMYUNDO,
JOSA_CHASU,
count(*) over (partition by SIDO,SIGUNGU,UPMYUNDO,JOSA_CHASU,GNUMBER) as cnt,
rowid as rid,
row_number() over (partition by SIDO,SIGUNGU,UPMYUNDO,JOSA_CHASU,GNUMBER order by rowid) as rn
from wamis_back.USE_GTESTITEM_SIDO) p
where p.cnt > 1
;partition by 함수를 사용하여 같은 값인지 비교할 컬럼들을 묶어주어 중복된 데이터를 조회한다
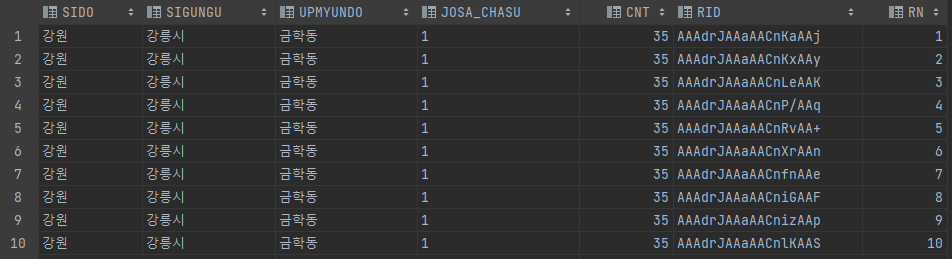
그럼 위와같은 결과를 얻을 수 있다
CNT은 중복된 데이터의 수이고
RN은 그 중에서 ROWID를 정렬해서 순서를 매긴 것이다
PARTITION BY
여러 개의 컬럼을 사용하여 그룹화 할 때 사용한다
분석함수([컬럼]) OVER(PARTITION BY 칼럼1, 칼럼2... [ORDER BY 절] [WINDOWING 절])
아래 함수들을 이용하여 사용할 수 있다
| 구분 | 분석함수 |
| 집계 | COUNT, MAX, MIN, SUM, AVG |
| 순위 | ROW_NUMBER, RANK, DENSE_RANK |
| 순서 | FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 통계 | STDDEV, VARIANCE |
| 비율 | RATIO_TO_REPORT, CUME_DIST, PERCENT_RANK, NTITLE |
참고
중복데이터 삭제
조회하여 나온 결과 중 하나를 남기고 삭제한다(IN 함수 사용)
delete
from wamis_back.USE_GTESTITEM_SIDO
where rowid in (
select p.rid
from (select rowid as rid,
row_number() over (partition by SIDO,SIGUNGU,UPMYUNDO,JOSA_CHASU,GNUMBER order by rowid) as rn
from wamis_back.USE_GTESTITEM_SIDO) p
where p.rn > 1
)
;중복데이터 조회를 했을 때 나온 RN값 중 1인 값을 제외하고 삭제하는 방식이다
728x90
반응형
'DB > ORACLE' 카테고리의 다른 글
| [ORACLE] 테이블 코멘트, 컬럼 정보, 컬럼 코멘트 조회 (0) | 2023.01.12 |
|---|---|
| [ORACLE] 테이블 구조 및 데이터 복사 (0) | 2022.12.21 |
| [ORACLE] 같은 테이블에서 자신의 컬럼으로 UPDATE (0) | 2022.11.22 |
| [ORACLE] 오라클 특정 문자열 치환/ 특정 문자열(특수문자) 제거(replace)/ ASCII 코드값 찾기 (0) | 2022.05.31 |
| [ORACLE] ORA-01578: ORACLE 데이터 블록이 파손되었습니다 (0) | 2022.04.05 |